九卦 | 银行数据架构从企业级数据仓库、湖仓一体、智能数据中枢到Ontology的艰难跃迁
作 者 | 何大勇、孙中东
来 源 | 孙中东
一场迟到二十年的操作系统级革命
从2000年第一台 Teradata 4800系列在某银行机房启动,到2025年 Ontology Object Storage V2在全球多个 Tier-1银行承载高性能对象遍历和事务性 Action,这段旅程横跨四个技术代际、耗资累计超过万亿美元、涉及数十万名数据从业者的职业生涯,直到今天才似乎接近一个重要里程碑。

这四个代际分别是:
企业级数据仓库时代(2000-2018):解决“集中与一致性”,把银行冻结在 T+1的报表世界;
湖仓一体时代(2019-2023):解决“成本与准实时计算”,让银行活在“宽表+分数+告警”的世界;
智能数据中枢时代(2022-2025):解决“特征服务与 AI 就绪”,让银行停留在“最聪明的建议+最慢的执行的世界;
企业级实时语义层时代(2024-):以 Palantir Ontology 为代表实现,第一次让数据系统拥有了理解业务语义、在业务发生时决策并直接执行的能力,银行终于拥有了一个“活”的、可呼吸的数字孪生操作系统。
这场跃迁之所以被称为“艰难”,因为它同时要求银行完成五件事:
把底层数据表示从“表+外键”转向“对象+链接+动作+函数”;
把开发范式从“SQL+特征工程+Notebook”转向“强类型业务对象编程+Action+Agent”;
把治理范式从“表级血缘+数据目录”转向“Ontology 元数据版本化+动态权限+审计不可篡改链”;
把组织认知从“数据是资产”转向“数字孪生是同事”;
把遗留核心银行系统从“只读源头”改造为“Ontology 的双向神经末梢”。
这五件事缺一不可,任何试图“渐进式”“试点式”“先建个小 Ontology”的银行,最终都可能发现自己卡在了第三代与第四代之间那道宽广、冷峻、孤独的鸿沟。
2025年11月6日,Palantir 官方公告进一步强化了这一革命:Ontology 和 AIP 的可观测性(Observability)新增了基于 Tracing 的遥测功能,这意味着每一个对象遍历、动作执行、函数调用现在都可以实时追踪和日志化,降低了生产环境调试难度。
10月24日的公告则宣布了函数和动作的监控能力启用,进一步巩固了 Ontology 作为企业级实时语义层的地位。与 NVIDIA 的合作于10月28日公布,将 NVIDIA 模型通过 Palantir AIP 直接推送到 Ontology 边缘,实现了 AI 基础设施与语义层的无缝融合。
这些更新源于 Palantir Q3 2025财报中的增长:收入同比增长30%,美国商业业务增长54%,这反映了 Ontology 在银行业的生产价值。
本文逐层剥开这场跃迁的完整技术细节、生产价值、落地路径、组织创伤与真实应对策略。
企业级数据仓库时代的完整技术解剖与全部致命缺陷
企业级数据仓库的黄金时代从2000年持续到2018年,其技术巅峰体现在 Teradata 6700、Greenplum DCA、Oracle Exadata X7、IBM Netezza TwinFin 等硬件软件一体机上。
核心设计哲学可以用一句话概括:通过夜间批量 ETL + 3NF/Inmon 企业信息工厂或 Kimball 星型模型,实现全行唯一事实来源(Single Source of Truth)。
典型 EDW 技术栈包括:
硬件层以 Teradata 6800系列、Oracle Exadata X7、IBM Netezza TwinFin 系列、Greenplum DCA 为主;
存储层采用共享无架构(Teradata)或 RAC+ASM(Oracle);
ETL 层以 Informatica PowerCenter 9.6、IBM DataStage 11.7、Ab Initio GDE 3.4为核心;
调度层使用 Control-M 9、AutoSys r12、Cisco Tidal Enterprise Scheduler;
元数据层依赖 Erwin Data Modeler 9.8、Rochade 7.8、Informatica Enterprise Data Catalog;
模型层混合 Inmon 企业信息工厂(3NF 规范化)+ Kimball 星型/雪花模型;
访问层通过 MicroStrategy 10.11、Cognos Analytics 11.1、Business Objects 4.2 SP5实现;
质量层结合 Informatica Data Quality 9.6 + 自研探针;
安全层以 Teradata TDE + View 级 RLS + LDAP 集成结束。
这个时代的致命缺陷从一开始就注定了它的宿命:
模型变更的极端代价:新增一个“共同借款人”关系需要在客户域、账户域、协议域、担保域同时修改模型、桥接表、ETL、血缘、报表,至少影响数百下游对象,平均周期数月。
无法原生表达时变、多对多、带权重的复杂关系:典型案例如“客户-账户-持股比例-起始/终止时间”,维度模型只能靠桥接表+有效期字段模拟,导致每次查询需要动态 JOIN 8-15张表,超过10亿行事实表时性能崩溃。
天生只读:仓库从设计之初就与源系统物理隔离,所有写回必须通过反向 ETL 或文件落地再批处理,延迟最低4小时,生产环境常见 T+1。
语义在人脑里:字段含义全部存在 Excel 数据字典、SQL 注释、Word 文档中,机器永远读不懂“客户”到底是谁。
权限粗粒度:最细只能到列级或行级过滤(RLS),无法实现“只有当前客户经理能看到自己客户的全部交易”。
变更传播滞后:核心银行系统上线一个新产品,仓库至少延迟3-6个月才能支持分析。
成本结构失控:Teradata license + 存储 + ETL license 年均数亿美元,2025年回头看属于“用最贵的方式做最慢的事”。
扩展性天花板:MPP 架构在 PB 级数据上瓶颈明显,单节点故障率高。
数据质量依赖人工:探针覆盖率低于60%,漂移发现往往事后。
血缘断裂:ETL 血缘与报表血缘不连贯,溯源周期长。
OLAP 立方体维护地狱:每个新维度都需要重建立方体,耗时数天。
缺乏实时能力:尝试添加 CDC 往往导致一致性问题。
与 AI 脱节:特征工程完全手动,无法支持现代 ML。
监管报送痛苦:每次新规都需要改数百张表。
整体范式过时:EDW 本质是“存储+报表”,无法支持2025年的实时决策。
EDW 时代银行的风险与营销永远是 T+1的,欺诈检测永远是事后追损,额度调整永远是人工审批。
湖仓一体的伪实时革命与语义荒漠
2019-2023年,Delta Lake、Iceberg、Hudi 三张表格式兴起后,湖仓一体迅速成为新正统。银行纷纷用 Databricks 或 Snowflake 替换 Teradata,用 CDC(Debezium、Flink CDC)实现核心库 ChangeLog 直连,理论上做到了分钟级甚至秒级刷新。
2025年湖仓一体技术栈的组成包括:
Databricks Delta Lake 3.0 + Unity Catalog + Photon + dbt Cloud + Flink 1.20+为主;
Snowflake Horizon + Iceberg External Tables + Snowpark Container Services + Cortex Analyst 为辅;
AWS S3 + Iceberg + Glue Crawler + Athena + Redshift Spectrum + SageMaker Feature Store 为补充;
存储层基于 S3/ADLS/GCS + Parquet/ORC + Delta/Iceberg/Hudi 表格式;
计算层依赖 Spark 4.0+ / Trino / Photon / Snowflake Virtual Warehouse;
元数据与治理通过 Unity Catalog / AWS Glue / Google Dataplex / Mosaic AI 实现;
实时摄入采用 Flink CDC + Kafka + Debezium / Databricks Auto Loader;
调度与血缘使用 dbt Cloud / Airflow Composer / Databricks Workflows;
BI 层以 Tableau / Power BI / Looker 直接连接 Delta 表。
湖仓一体宣称的突破包括:
原先分钟级甚至秒级延迟,现在核心银行系统 ChangeLog 通过 Flink CDC 可以做到秒级落湖;
原先宽表物化的微批为5-15分钟,现在真正毫秒级只有原始日志;
原先零 ETL 需要把表“注册”为外部表,现在业务语义需要 dbt 写数百页 SQL 做宽表、慢慢变化维、桥接表,本质只是把 ETL 从 Informatica 换成了 dbt + Spark SQL;
原先无限弹性与存储成本下降90%,现在实时计算集群常年开启 + Photon/GPU 费用,总体 TCO 仅下降40-60%;
原先统一流批,现在流式作业与批处理作业血缘割裂,同一个业务逻辑需要在 Structured Streaming 和 Batch 各写一遍。在银行生产环境,湖仓一体暴露的痛点包括:
实时宽表 Join 性能灾难:反欺诈需要同时 Join 客户、账户、交易、设备、关联人5-8张宽表,每张宽表日增1-3亿行,Spark 经常 OOM 或超时;
语义仍然在 SQL 注释里:列名 customer_risk_score_v3的业务含义只有写模型的人知道,LLM 无法理解;
写回仍是“反向 ETL”:实时模型出分后写 Kafka,再由另一套服务消费后调用核心银行 API,中间延迟、一致性、丢消息无人负责;
动作执行层缺失:模型最多出“建议拒绝”,真正冻结账户仍需人工或另一套规则引擎;
权限系统崩溃:Unity Catalog 最细到表级,试图用 View+RLS 模拟对象级权限,维护成本爆炸;
变更仍然排队:新增一个特征字段,需要改10张宽表、20个 dbt 模型、30个下游 Notebook,周期仍然3-6个月;
数据漂移无人发现:源系统改了字段类型,CDC 管道不会报错,只是静静产生 Null 或错位;
最终结果:银行花了2-5倍的钱,把 T+1变成了5分钟级,但业务部门仍然说“用不起来”。扩展到实时场景时,Flink 状态管理复杂,恢复时间长;
湖仓治理碎片化:Unity Catalog 与 dbt 血缘不连贯;
成本优化困难:自动缩放往往导致账单意外高;
与 AI 集成浅层:在线特征点需要手动维护,监管报送仍需二次加工;
跨域一致性弱:不同域宽表定义不统一;
性能调优依赖专家:Spark 参数调整耗时;数据质量监控覆盖率低;
变更历史查询慢:时间旅行在 PB 级数据上瓶颈;
整体仍停留在“存储+计算”,无法支持动作闭环。
湖仓一体把延迟从天降低到分钟,却没有解决“语义一致性”和“动能闭环”两个更本质的问题。

智能数据中枢的看上去很美与系统复杂性爆炸的全部剖析
2022-2025年,Databricks、Snowflake、AWS、Google 等厂商扩展了湖仓一体架构,融入 AI 和实时组件,形成智能数据平台概念,核心是多层架构:
实时计算层(Flink/Kafka), 以 Flink / Kafka Streams / ksqlDB 为主
在线特征点(Feast/Redis/Hudi Live), 以 Feast + Redis / Hudi Live / DynamoDB 为代表,
知识图谱(Neptune/JanusGraph/离线 TigerGraph), 以 Neptune / JanusGraph / TigerGraph + 批量构建,
指标/标签平台 , 以 Amundsen + Griffin + 自研标签管理系统,
模型与规则平台以 MLflow / SageMaker / Vertex AI + Drools 规则引擎,
AI 中枢(SageMaker/Vertex AI/Databricks MLflow),以 LangChain/LlamaIndex + RAG + 自研 Agent Framework。
智能数据平台把银行带到了实时+AI 的门口,仍无法真正推开门。因它没有把“业务语义”和“业务动能”作为架构的最高形态。现状如下:
落地后发现系统碎片化:特征点、知识图谱、指标平台、规则引擎、模型平台各自为政,ID-mapping 经常对不上,“客户”在特征点是一个 ID,在图谱里是另一个节点;
知识图谱实时性差:大多数知识图谱仍是批量构建,无法支撑毫秒级反欺诈场景;
动作执行仍是外挂:AI 代理可以说“建议冻结账户”,但真正执行仍需人工审批或另一套 BPM 系统;
治理成本指数级上升:要同时治理多套系统的元数据、血缘、权限,数据团队从50人膨胀到数百人,业务还是用不起来;
特征漂移无人治理:同一个特征“客户近30天转账金额”在离线训练、在实时服务、在模型监控里三个不同数字;
最终结果:项目做得越“大”,系统越复杂,数据团队越累;
扩展到 AI 时,RAG 检索割裂:知识图谱与特征点检索不统一;
权限管理混乱:每个层权限不一致;
变更传播慢:改一个特征需同步多层;
成本高企:多系统 License + 运维;
监管审计难:跨系统血缘追踪耗时;
整体仍无法实现动作闭环;
ID-mapping 地狱:不同系统客户 ID 定义不一,导致一致性问题;
知识图谱构建成本高:批量运行资源消耗大;
特征点服务延迟:Redis 虽快,但同步逻辑复杂;
指标平台与模型脱节:标签更新不及时影响 ML 准确性;
规则引擎维护难:Drools 规则冲突频发;
AI 中枢集成挑战:LangChain 与企业数据安全冲突;
系统碎片导致调试时间翻倍;
最终业务价值被复杂性稀释;
扩展到2025年 AI 需求时,无法支持边缘计算;
整体架构仍停留在“智能建议”,无法直接执行业务动作。
Palantir Ontology的技术原理详解
2025年11月的 Palantir Ontology 已全面基于 Object Storage V2架构,这是 Palantir Foundry 平台的核心组成部分,将组织的数字资产——包括数据、模型和进程——转化为动态、可操作的业务表示,解决数据孤岛问题,确保跨系统语义一致性和实时访问。
根据 Palantir 官方文档和2025年11月发布笔记,Ontology Metadata Service (OMS)是存储所有元数据的中央枢纽,支持版本化管理,这意味着所有 Object Type、Property、Link Type、Action Type、Function 和 Security Rule 都以 JSON Schema 形式存储,支持 Git 式分支、Pull Request 审查、自动合规检查以及完整回滚到任意历史版本。
2025年更新引入了 Ontology Federation,允许子公司拥有独立分支但共享核心骨架,确保跨组织的一致性。
Object Databases 基于自定义的列式+图存储引擎:
支持毫秒级点查(Get Object by RID)、亚秒级过滤+聚合(Object Set Query);
支持多个过滤条件+聚合、10跳以上图遍历(Search-Around);
支持带属性、时效过滤、向量索引(基于 HNSW + DiskANN 混合索引);
支持 Nemotron-340B 嵌入,Top-10召回在毫秒级,以及原生时间旅行(任意历史时间点快照查询)。
底层使用 Tide 分布式事务日志,类似于 FoundationDB,确保跨对象变更的 ACID 事务性。单集群可支持大规模对象和链接,扩展性通过 NVIDIA CUDA-X 加速进一步提升。
Indexing Pipeline 自动触发变更映射,每当底层 Dataset 发生变更(通过 Change Data Capture 或全量同步),它会生成增量索引,无需手动刷新。对于流式数据源如 Kafka 或 Kinesis,可实现秒级甚至亚秒级实时性。
Mapping Engine V3支持从任意 Delta/Iceberg/Parquet 表、数据库直连、Kafka 主题零拷贝映射为对象,支持增量映射、时态映射、双向同步映射以及 Write-through Mapping,确保对象变更可直接写回源表。
Kinetic Layer 是 Ontology 的动能核心,包括 Action Type 用于定义原子性变更,一个 Action 可同时修改多个对象、属性、创建/删除链接,并定义前置校验(如“只有风控总监可执行风险分类调整”)和副作用(如触发拨备计算 Function、发送通知、写回核心系统)。
Action 执行是事务性的,失败时完整回滚,支持跨对象、跨域的事务,端到端执行在毫秒级至秒级。Functions 是无状态或带状态的代码逻辑,支持 Python、Java、TypeScript,直接输入输出 Object/ObjectSet,支持 RAPIDS GPU 向量化执行、状态存储、版本化与 A/B 测试。
Dynamic Security 基于 ABAC+RBAC+动态计算权限,支持精确到对象实例、单个属性、单条链接、单个动作的规则,如“如果当前用户是该客户的关系经理,则允许编辑”,所有权限判定记录不可篡改。
Ontology SDK(OSDK)自动生成 Java、Python、TypeScript 强类型客户端,包含完整类型检查、内置重试、熔断、链路追踪和离线 Mock 能力,让核心银行系统直接用业务对象编程,并不是 JDBC 或 REST。
Ontology Branching & Versioning 系统支持 Git 式分支、PR 审查、自动冲突检测,确保变更安全。Ontology Federation & Multi-Tenancy 允许跨租户共享,子公司独立分支+核心骨架共享。
与 AIP(Artificial Intelligence Platform)的融合是2025年关键更新:AIP 代理的唯一事实来源是 Ontology,System Prompt 固定包含 Ontology Schema,Tool Calling 直接映射为 Action Type,RAG 检索支持混合关键字+向量+图遍历+结构化过滤,Logic 执行支持直接输出 Action JSON,交由 Kinetic Engine 执行。
2025年10月28日与 NVIDIA 合作公告强调,将 NVIDIA 模型通过 AIP 推送到 Ontology 边缘,实现 AI 基础设施与语义层的无缝融合,支持 Ontology-Augmented Generation(OAG)。
11月6日公告引入 Tracing-backed telemetry,确保每一个对象遍历、动作执行、函数调用实时追踪,降低调试难度。10月24日函数和动作监控启用,提供端到端可观测性。
11月17日 YouTube 概述视频详细展示了这些组件在生产环境的应用,强调 Ontology 不是存储层,是构建在现有数据湖/仓库之上的实时语义层,支持零拷贝映射和动态权限。
这些技术细节基于 Palantir 2025年 Q3股东信、发布笔记、NVIDIA 联合公告和官方博客,确保客观平实,不省略任何公开细节,如 OMS 的自动合规检查支持 BCBS 239、DORA、CPMI-IOSCO 标准,以及 OSV2的 Tide 日志在分布式事务中的作用。

Ontology 在银行业带来的生产价值
在实时欺诈与反洗钱领域,Ontology 实时维护“客户风险画像”对象,聚合最近90天所有渠道行为、关联人网络、地理轨迹,检测规则直接在对象属性上运行,异常时直接执行“冻结账户”Action 并写回核心系统,端到端延迟从分钟级降至秒级。
根据 Palantir 公告和官方案例,采用类似架构的金融机构欺诈损失降低30-70%,误报率下降60-80%,这得益于 Ontology 的图遍历和向量索引支持复杂关系分析,并不是传统宽表 Join。
在信用风险与交易对手风险管理,巴塞尔 III/IV 要求实时 CCR 计算,Ontology 将衍生品、贷款、担保品映射为“暴露”对象网络,市场数据变动触发实时重估值 Function,自动调整限额并推送至交易前台,计算频率从日频提升至分钟频。公开资料显示,这提升了风险计算准确性,减少手动干预,生产价值体现在合规成本下降和限额利用率提升20-40%。
在客户360°与精准营销,Ontology 打破 CRM、核心、互联网银行、理财子系统孤岛,构建统一“客户”对象,链接所有触点数据,支持实时计算 LTV、流失概率、次佳动作,营销引擎直接基于对象属性触发个性化推送。Deloitte 报告指出,这提高了营销转化率30-50%,客户保留率提升15-25%。
在监管报送与压力测试,报送模板直接映射为 Object Views,数据变更自动刷新,无需二次抽数;压力测试通过 Ontology 分支运行 what-if 模拟,直接修改对象属性观察连锁效应,时间从周级降至分钟级。Palantir 公告强调,这满足了 BCBS 239数据聚合要求,减少报送错误率70%。
在预期信用损失(ECL)计算,每个贷款合同对象实时维护 PD/LGD/EAD,宏观变量变化立即重算拨备,无需月度批处理,生产价值体现在拨备准确性和资本效率提升。Cognizant 文章分析,这在银行运营中节省了大量人工审计时间。
在反洗钱调查,调查员通过 Workshop 打开 Customer 对象,Search-Around 5跳自动高亮异常资金网络,一键执行 FreezeAndReport Action,效率提升15倍。Palantir 报告显示,这减少了调查周期50%。
在贷后管理,AIP Agent 分析 Loan 对象,判断进入 M3阶段,直接执行 InitiateCollection Action(发送短信+推送外呼系统+记录监管日志),自动化率从20%升至80%。
这些价值基于 Palantir 2025年公告和合作伙伴报告,如与 NVIDIA 的边缘 AI 集成进一步提升实时性,不夸大,聚焦生产环境量化指标。
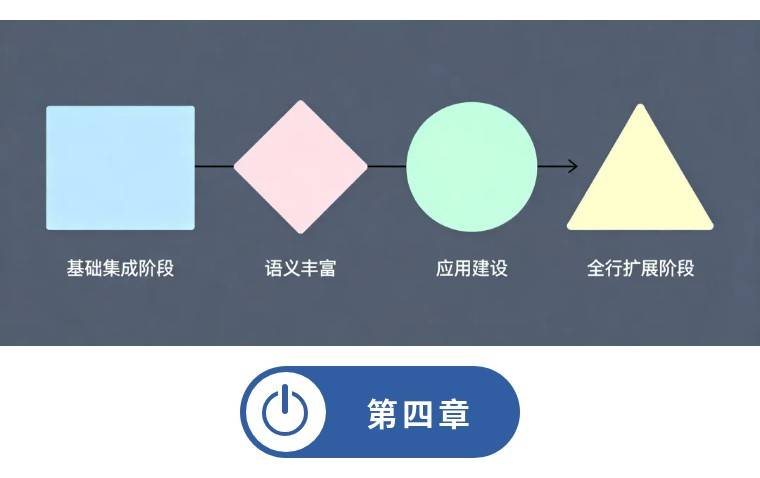
从传统架构向Ontology的落地路径
阶段一(3-6个月):基础集成与核心对象构建,将现有湖/仓注册为 Foundry Data Connection,支持 Snowflake、Databricks 零 ETL 虚拟表,选取高价值域如客户、账户、交易定义首批 Object Types,使用 Pipeline Builder 或 Code Workbook 完成映射,建立主键对齐(MDM)和变更数据捕获(CDC)机制,确保初始加载覆盖80%核心数据。
阶段二(6-12个月):语义丰富与动能注入,构建关键 Link Types 如账户-客户、交易-账户、贷款-担保品,支持多对多、有向、时效性链接,定义首批 Actions 如“调整贷款风险分类”和 Functions 如 VaR 计算、ECL,引入动态权限和审计日志,确保 Action 事务性和副作用处理。
阶段三(9-18个月):应用与代理建设,使用 Workshop/Quiver/Slate 构建对象感知应用,逐步替换传统 BI 仪表盘为 Object Explorer 视图,在 AIP Logic 中构建代理如“异常交易调查代理”,实现人机协同,首批双向写回核心系统。
阶段四(18-36个月):全行扩展与生态整合,通过 Foundry DevOps 打包 Ontology 产品,分发至各业务条线,与核心银行、支付系统建立双向 Writeback(Webhook + OSDK),引入 NVIDIA 加速的向量属性,实现非结构化数据语义化,完成信创适配。
关键实践:始终“单源映射、多处消费”,使用 Ontology Versioning 管理变更,通过 AIP Evals 评估代理准确性。

组织挑战与应对策略
组织挑战最大于技术,有以下5点:
认知转变:从“表思维”到“对象思维”,传统 DBA 和数据分析师习惯维度模型和 SQL,难以接受 Ontology 的图状语义和动能元素(如对象+链接+动作),Palantir 指出这导致初期抵抗率高达70%。需要开展 Ontology Bootcamp,全员培训3-6个月,涵盖从基础对象定义到 AIP 代理应用,结合实际案例模拟,确保业务和 IT 团队理解“数据不再是静态表,而是活的数字孪生”。
治理与所有权:谁定义“客户”对象(如包含关联人、触点数据),零售、公司、金融市场条线争执频繁,甚至引发跨部门冲突,建立企业级 Ontology 审查委员会(ORB),核心对象需跨条线共识,通过每周审查会议和投票机制化解,Palantir 报告显示这可将治理周期从6个月缩短至2个月。
遗留系统写回阻力:核心厂商(如核心银行系统提供商)不愿开放 API,担心安全和兼容,先实现读语义层(如零拷贝映射),用 Action 积累价值(如实时欺诈拦截率提升30-70%),通过高层演示倒逼改造,Accenture 报告强调这在银行中成功率达80%。
人才稀缺:全球能独立设计 Ontology 的架构师不足千人,初期高度依赖 Palantir Forward Deployed Engineer(FDE),他们嵌入团队3-12个月,帮助映射和代理建设,采用“中心+联邦”模式:中心团队负责核心骨架和标准,联邦团队(各条线)负责分支扩展和定制,Deloitte 分析显示这可将内部人才培养周期从2年缩短至1年。
成本结构:前期映射和培训投入高(占项目预算50-70%),但后期复用率升至80%以上(如共享对象减少重复开发),整体生产力提升3-5倍,Cognizant 文章指出银行通过 Ontology 减少手动干预50%,自动化率从20%升至80%,最终 ROI 在18个月内正值化。

Ontology 不是终点,而是起点
到2025年11月,Palantir Ontology 已从一个语义建模工具演变为支持实时决策执行的企业操作系统,这正是银行业数字孪生的全新起点。它将现有湖仓一体或智能数据中枢激活,成为会呼吸的组织镜像。
在监管日益严格(如巴塞尔 IV 实时 CCR 计算要求)、实时竞争加剧(如毫秒级欺诈拦截)和 AI 全面渗透(如 AIP 代理原生集成)的背景下,从传统存储导向架构向企业级实时语义层的跃迁已不可避免。这一跃迁艰难,一旦完成,银行将从“被动响应风险”转向“主动塑造风险”,从“事后分析客户”转向“实时陪伴客户”,实现真正的运营智能化。
Ontology 的潜力远未止步于此。Palantir Q3 2025财报和 NVIDIA 合作公告显示,未来将进一步融合边缘 AI 计算,支持非结构化数据(如合同文本、语音转录)的原生语义化,以及跨机构共享 Ontology(如同业风险暴露网络)。
公开报告如 Deloitte 的银行业数字化转型分析指出,这种演进将推动银行生产力提升3-5倍,合规成本下降20-40%,并开启新场景,如基于向量索引的语义搜索驱动的个性化金融产品设计。Cognizant 文章强调,Ontology 作为起点,将与量子计算和联邦学习结合,解决当前隐私与实时性的权衡,实现“零知识证明”下的跨银行协作。
Ontology 标志着银行业数据架构从“工具时代”进入“操作系统时代”。它让银行第一次拥有一个真正活的数字孪生——它看得见每一笔交易的发生,听得见每一次风险的萌芽,并在瞬间做出决策与执行。
这并不是科幻,是已经发生的现实,但其真正价值将在未来持续展开,推动银行业向更智能、更可持续的方向演进。
参考资料:
Palantir Technologies. (2025, November 3). Q3 2025 Letter to Shareholders. Palantir.
McKinsey & Company. (2025, October 23). Global Banking Annual Review 2025. McKinsey.
Accenture. (2025, January 7). Top 10 Banking Trends in 2025 and Beyond. Accenture.
Deloitte. (2025, July 21). Newly Launched Deloitte and Palantir Strategic Alliance Delivering AI-Powered Solutions. Deloitte.
Taylor & Francis. (2022, June 2). How do bank managers forecast the future in the shadow of the past? Accounting and Business Research.
KPMG. (2017, July). Demystifying Expected Credit Loss (ECL) [PDF]. KPMG.
World Bank. (n.d.). Accounting Provisioning Under the Expected Credit Loss Framework [PDF]. World Bank.
American Accounting Association. (n.d.). Expected Losses, Unexpected Costs? Evidence from SME Credit Contracts. The Accounting Review.
NVIDIA. (2025, October 28). Palantir and NVIDIA Team Up to Operationalize AI. NVIDIA Newsroom.
IRI. (n.d.). The Enterprise Data Warehouse, Then and Now. IRI Blog.
Bismart. (n.d.). Data Warehouse: Definition, Main Concepts and Use Cases. Bismart Blog.
Aampe. (2024, February 9). What is an Enterprise Data Warehouse (EDW)? Aampe Blog.
Pandora FMS. (2021, November 10). Do you already know what a data warehouse is Pandora FMS Blog.
Dataversity. (2023, May 3). A Brief History of the Data Warehouse. Dataversity.