没想到!一个不起眼的架构优化,节省了超1000万美元云成本……
这不是一个关于花哨的机器学习或亿级用户规模的故事。
这是一个关于某个架构决策的故事,它悄然无声,几乎不为人知,却在三年内最终为公司节省了超过1000万美元。
- 它并不引人注目
- 它没有赢得奖项
- 但它改变了一切
如果你从事高流量服务的工作,如果你的数据库账单持续攀升,或者如果你的 Kubernetes 集群持续消耗越来越多的云积分,却没有明确原因……
这个故事可能会改变你对架构的思考方式。
我们基础设施账单无故激增的那个月
那是一个周五的下午。仪表盘亮起了红色——不是因为服务中断,而是因为我们当月的 AWS 费用预测比上个月暴涨了 38%。
- 我们没有运行批量作业
- 没有重大的产品发布
- 没有新增区域
- 仅仅是流量略有增加
但不知何故,我们的基础设施成本爆炸式增长了。
我收到了通常的 Slack 消息:
"有新的自动扩缩容配置吗?"
"有人改了实例类型吗?"
"也许只是 CloudWatch 抽风了?"
不,都不是!
我们即将通过艰难的方式,学习关于数据库连接的昂贵一课。
连接洪泛的隐藏成本
我们的架构在纸面上看起来"没问题"。
我们有几十个 Spring Boot 微服务。每个服务都有自己的到 PostgreSQL 的连接池。
自动扩缩容是开启的。流量上升,Pod 会启动,一切都会弹性扩展。
除了……每一个新的 Pod 都会带来 50-100 个新的数据库连接。
而且我们在 4 个区域部署。
我们来算一下:
- 12 个微服务
- 每个服务 3 个副本
- 4 个区域
- 每个 Pod 100 个连接(默认的 Hikari 连接池大小)
这相当于对同一个数据库集群有超过 14,000 个潜在的并发连接。
而我们的数据库呢?
它正悄无声息地在重压下窒息。
我们的架构原来是这样的:
┌─────────────┐
│ Service A ├─────────┐
└─────────────┘ │
┌─────────────┐ │
│ Service B ├────────────┐
└─────────────┘ │ │
┌─────────────┐ ▼ ▼
│ Service C ├──────▶ PostgreSQL
└─────────────┘ ▲ ▲
... │ │
┌─────────────┐ │ │
│ Service N ├─────────┘ │
└─────────────┘ │
Hundreds of long-lived connections
每个 Pod 都是一个滴答作响的成本炸弹
理论上,连接池是高效的。
但实际上?
随着自动扩缩容、部署、回滚以及蓝绿策略——同时存在的连接数量会激增,即使流量没有增加。
我们当时在支付:
- 我们并未使用的连接
- 数据库内存峰值
- 更多的只读副本
- 更大的实例
- 更高的网络传输费用
我们的 PostgreSQL 集群开始静默地故障。
延迟上升。垃圾回收活动加剧。
突然间,每个微服务看起来都像是罪魁祸首。
但真正的罪魁祸首是我们的架构。
改变一切的决策
我们没有重写我们的服务。
我们没有更换数据库。
我们没有转向 NoSQL 或者引入 Kafka 来"解耦"。
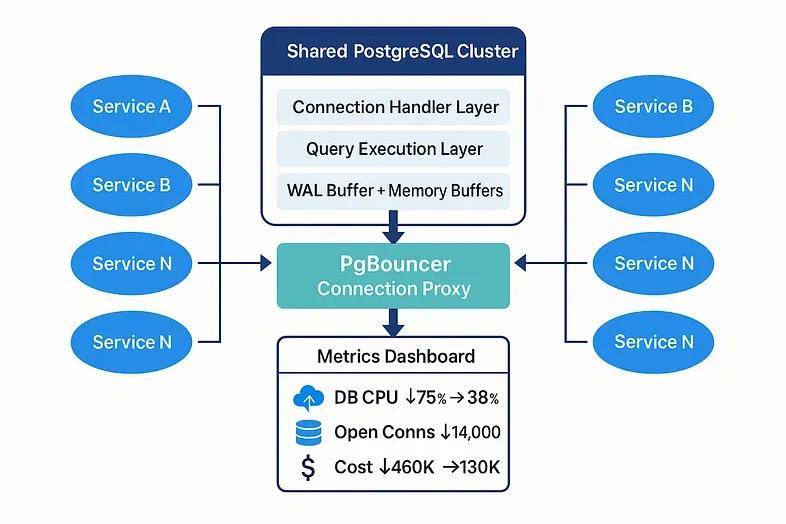
我们所做的一切只是引入了一个共享连接代理——PgBouncer,以事务池模式运行在我们的 Kubernetes 集群内部。
现在,每个微服务不再直接与 PostgreSQL 对话,而是与 PgBouncer 对话。
PgBouncer 复用了连接,它汇集了它们,并给了 PostgreSQL 喘息的空间。
几乎一夜之间,我们的成本图表变成了这样:
┌──────────────┐
│ Service A ├──────┐
└──────────────┘ │
┌──────────────┐ ▼
│ Service B ├──▶ PgBouncer ──▶ PostgreSQL
└──────────────┘ ▲
... │
┌──────────────┐ │
│ Service N ├──────┘
└──────────────┘
Connection pooling handled outside the app
为什么 PgBouncer 效果如此之好
- 它及早终止连接(事务模式意味着它一旦查询完成就将连接返回给池。)
- 它显著减少了打开的连接数量(从约 14,000 个减少到 < 400 个稳定连接。)
- 它保护 PostgreSQL 免受连接风暴的冲击(在部署或故障转移期间不再出现峰值。)
- 它让服务启动更快(不再需要等待完整的连接池或数据库握手。)
而所有这些,都是在没有触碰任何一行应用逻辑代码的情况下完成的。
我们如何部署它(Spring Boot 设置示例)
从服务端来看就是这么简单:
yaml
# application.yml (Spring Boot)
spring:
datasource:
url: jdbc:postgresql://pgbouncer-cluster:6432/mydb
username: myuser
password: ${DB_PASSWORD}
hikari:
maximum-pool-size: 20
minimum-idle: 5
idle-timeout: 30000
connection-timeout: 20000
max-lifetime: 600000
注意端口号——6432。
那是 PgBouncer 的默认端口。
业务逻辑无需改变。只是把 JDBC 连接字符串指向了 PgBouncer。
我们的实际收益(没有基准测试,只有真实结果)
我们没有编写合成的基准测试。
我们在上线后观察了真实的生产指标:
- 数据库内存使用量下降了 47%
- Pod 启动时间减少了 22%
- 负载下的数据库 CPU 使用率从 75% 降至 38%
- 数据库集群规模减半(从 12 个节点减少到 6 个节点)
- 云账单每月下降了超过 30 万美元
将这些收益推算三年?
节省了 1080 万美元。
没有新的框架,没有戏剧性的重写,仅仅是一个小小的架构转变。
为什么没人谈论这个
因为它很无聊。
没有工程师想在 LinkedIn 上发帖说:
"我们添加了 PgBouncer,节省了数百万美元。"
- 它不是"颠覆性"的
- 它不是一种新范式
- 但它是我们做过的影响最深远的改变之一
架构并不总是关乎创新。有时候,它关乎消除那些甚至没人意识到的摩擦。
你什么时候应该使用这个?
在以下情况下,你应该考虑使用 PgBouncer(或 RDS Proxy,或任何连接池代理):
- 你运行着 10 个以上具有自动扩缩容功能的微服务
- 你的数据库在部署期间显示高内存或 CPU 使用率
- 你经常遇到 max_connections 错误
- 你支付更大的数据库集群费用只是为了避免随机超时
- 你的服务有时在启动时因等待数据库而挂起
如果你正在经历以上任何一种情况,那你可能正在悄无声息地浪费资金,就像我们当初一样。
我们学到的(但没人告诉我们的)经验
1、默认的连接池大小是危险的
HikariCP 允许设置为 100 并不意味着你应该这么做。
2、自动扩缩容可能会破坏你的数据库
可以扩展计算资源,但应该集中管理连接。
3、架构才是真正节省成本的地方
不是在代码里。不是在缓存里。而是在服务之间通信的方式里。
4、没人会因为解决看不见的问题而获得赞誉
但看不见的问题往往是代价最高的。
为什么这个故事对我很重要
我们在代码审查期间没有发现这个问题。
它没有出现在我们的单元测试中。
也没有出现在我们的负载测试中。
也没有出现在我们的 CI/CD 仪表盘中。
它出现在我们的财务报表上。
这就是架构变得真实的地方。
当它不再是理论——而是开始以百万美元的条目出现时。
最后一点想法
你不需要重写你的后端来节省数百万美元。
你只需要审视你正在扩展的是什么——以及它是在帮助你还是在伤害你。
而如果你正在扩展的是连接数而不是吞吐量?
你可能已经在付出代价了。
你是否遇到过类似的扩展瓶颈?
你使用了 PgBouncer、RDS Proxy 还是其他方案?
欢迎留下您的评论,让我们一同分享那些虽未收获足够赞誉,却始终在幕后为我们系统保驾护航的故事。
作者丨The Atomic Architect 编译丨Rio
来源丨网址:https://medium.com/@the_atomic_architect/how-one-architecture-decision-quietly-saved-us-10-million-and-nobody-noticed-until-it-was-gone-b4ddf0e0d874
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn